Imagine both Googlebot and Bingbot being smarter – much smarter. Instead of just grabbing text and links and pictures from pages, they might instead read those pages and extract facts about specific people and places and things from them, often referred to as named entities. They may associate facts with those entities, and classify them based upon attributes and concepts they find online or within their query logs about them.
These facts and concepts found in this knowledge base may also be about your business or the products you sell, or your reputation itself.
The search engines may calculate probabilities about how well those facts and concepts match up against those entities. This association can influence what shows up in search results and how those are ranked, and in query suggestions, and query refinements.
Related Content:
The search crawling programs might also tag or label the content they find on pages, based upon other information that they might know about what they come across on other pages on the Web, or in the Google and Bing query log files or click log files.
For example, the following query suggestions appear in a drop down under a search box for Virginia’s Republican candidate for Governor in an election to be held this week:
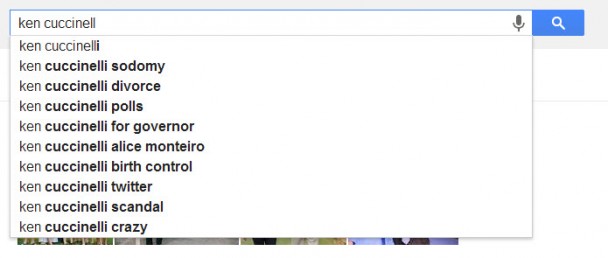
When Google introduced their Hummingbird update recently, we were told by Google that it would better handle conversational searches by re-writing queries to sometimes include appropriate synonym or substitute terms, and fit better with all of the meaningful words within a query.
Imagine the crawling programs from Google and Bing better understanding the text of web pages, and Tweets and status updates. Imagine Google and Bing using the concepts found in those to rank pages differently, using that information.
Both Google and Microsoft have published papers and patents that are showing off how they might transform search in the future by learning as much as they can about specific people, places, and things. Google purchased MetaWeb a couple of years ago, which operates the knowledge base Freebase. Both Google and Microsoft both display a knowledge panel in their search results, especially when it comes to named entities.
For example, a search for the 16th president of the United States shows off facts about him that not only come from places like Wikipedia but also use query log file information from sources like Google to answer and to anticipate other searches.
Google’s knowledge panel about Lincoln includes his “height,” which is an attribute not shown for other US Presidents because height is something that many Google searchers search about when it comes to Lincoln and Google knows that from its query logs:
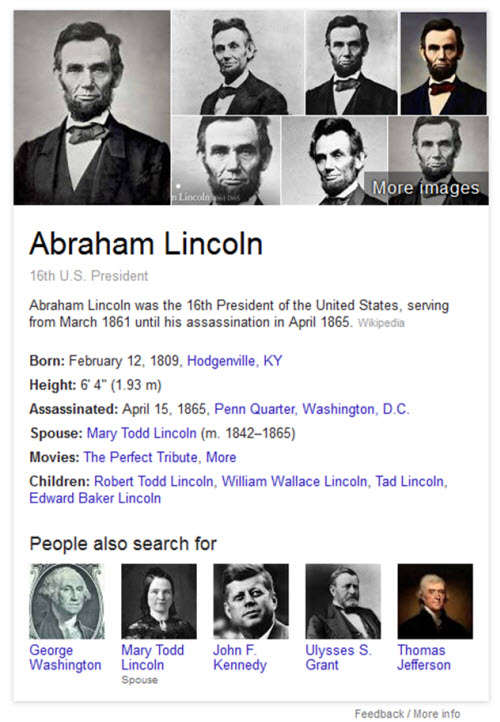
If you search for a basketball player, height is something that Google seems to consider an automatic attribute to report upon for basketball players, regardless of whether you’re 7’7″ like Manute Bol or 5’3″ like Muggsy Bogues. It’s not an attribute that is commonly displayed for presidents though.
Bing’s knowledge panel shows facts as well, within categories or attributes that it thinks people are interested in, and also reveals that it is looking at other sources of information as well such as Twitter and Quora and blog posts:
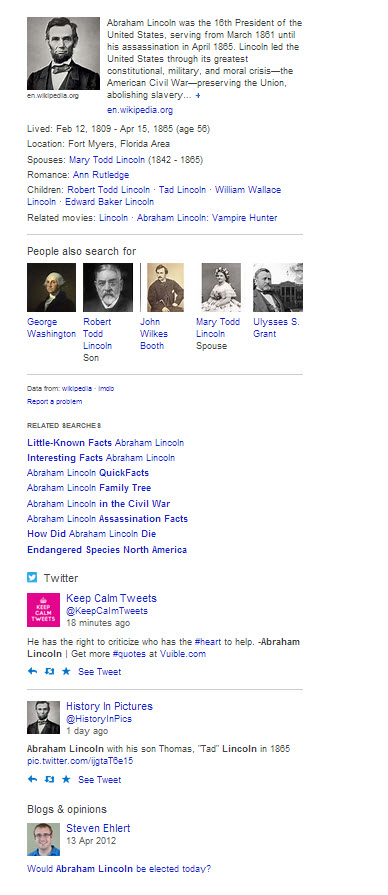
With both Google and Bing showing off facts about specific people, places, and things like this, both search engines are transforming into knowledge bases. Given Larry Page’s renaming of Google’s “search” division into their “knowledge” division, it seems like an intentional transformation.
In a white paper from last year, Wentao Wu of the University of Wisconsin, Hongsong Li and Haixun Want of Microsoft Research Asia, and Kenny Q. Zhu of the Shanghai Jio Tong University published Probase: A Probabilistic Taxonomy for Text Understanding (pdf) for SIGMOD ’12 in May, held in Scottsdale, Arizona. The purpose behind Probase is described on Microsoft’s page about the project:
The goal of Probase is to make machines “aware” of the mental world of human beings so that machines can better understand human communication. We do this by giving certain general knowledge or certain common sense to machines.
At the time when this paper was written, the Probase database contained 2.7 million concepts that were gathered from 1.68 billion web pages. The difference between Probase and other knowledge bases, as noted in this paper, is that it uses probabilities to identify how different concepts might be related to each other. One of the goals of the paper is in;
- Describing how a taxonomy was constructed that describes those relationships
- How probabilities were assigned to this concept model, and
- How it might be used in different applications to better understand text
When we start entering a term into a search box at Google, we see suggested queries related to that term appear as suggestions. The search results for those terms might include some query refinements as well. The query suggestions from a search box, or query refinements within search results may sometimes contain very helpful information for searchers exploring a topic related to their query.
Sometimes those also include terms that might not be very complimentary. Knowledge base results may also include things that could potentially cause harmful or prejudicial material to appear as well.
Wikipedia is a knowledge base that many people are familiar with, and it is the source for a lot of the “facts” that show up in knowledge panels at both Google and Bing. Wikipedia limits the kinds of information that might be written about living people within entries for them because:
…living persons may suffer personal harm from inappropriate information.
The Web is not policed by Wikipedia editors, and neither are the queries that people search for, so there’s a possibility that harmful information from many sources across the Web and in query and click log files might make its way into the knowledge bases at Google and Bing.
Regardless of that, search engine results will likely be transformed by knowledge bases such as Probase, which try to understand the relationships between entities found on the Web. We see that attempt at understanding with Hummingbird, which aims at understanding words and concepts within queries better. It’s just the start.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: